
Anthropic Just Dropped Claude Opus 4.8.
Here Is Everything That Changed

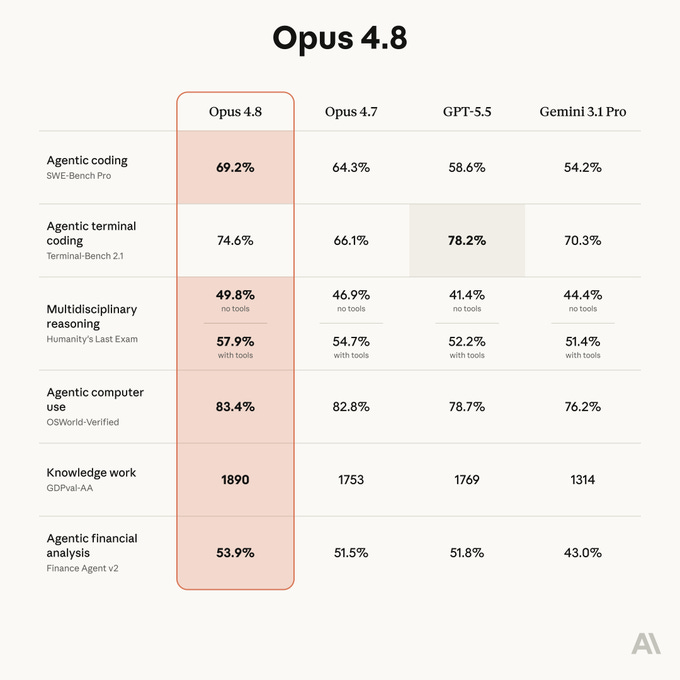
Anthropic released Claude Opus 4.8 today, and it outperforms its predecessor across most major benchmarks while beating OpenAI’s GPT-5.5 and Google’s Gemini 3.1 Pro in several key categories.
The model still lags Mythos, Anthropic’s most advanced model, but Anthropic says Mythos-class models are expected in the coming weeks.
The release cadence is worth n…
Keep reading with a 7-day free trial
Subscribe to The VC Corner to keep reading this post and get 7 days of free access to the full post archives.